
Thomas Baudel(c)
Thèse de Doctorat en Informatique
sous la direction de Michel Beaudouin-Lafon
soutenue le 15 décembre 1995
à l'Université de Paris Sud
The machine was rather difficult to operate. For years, radios had been operated by means of pressing buttons and turning dials; then, as the technology became more sophisticated, the controls were made touch sensitive ... now all you had to do was wave your hand in the general direction of the components and hope. It saved a lot of muscular expenditure of course, but meant you had to stay infuriatingly still if you wanted to keep listening to the same programme.
D. Adams, The hitch-hikers guide to the galaxy. Ch. 12.
Malgré les attraits mentionnés des interfaces gestuelles pures et l'importance des recherches menées, en particulier aux États-Unis, dans le domaine des réalités virtuelles, très peu d'applications ou même de prototypes convaincants ont été proposés dans ce domaine. On peu citer les travaux de D. Sturman [Sturman 1992], ou quelques travaux d'analyse des langues de signes des sourds-muets [Murakami et Taguchi 1991], [Kramer 1993]. Cependant, aucun de ces travaux ne débouche sur des possibilités d'utilisation pratique hors de contextes très particuliers. Nous nous sommes donné pour but de fournir un exemple d'interaction gestuelle utilisable dans un contexte réel. Notre démarche consiste à nous appuyer sur les caractéristiques (apports et limites) propres au geste, pour déterminer une méthode d'interaction adéquate, puis en déduire des algorithmes de reconnaissance des gestes efficaces.
* Interaction plus naturelle : La communication gestuelle avec une machine fait appel aux moyens de communication humains naturels. Certains signes, plus ou moins universels, sont utilisés instinctivement dans certaines situation : confirmation, désapprobation, expression d'une envergure, ou de "passage à la suite".
* Interaction plus concise et plus efficace : l'aspect dynamique du geste est porteur d'informations supplémentaires ; l'utilisateur peut exprimer en une seule action une commande, et, par des variations dans l'aspect dynamique, préciser des paramètres tels que la portée de la commande ou les objets la concernant. La prise en compte de la dynamique gestuelle permet donc d'élargir la bande passante du canal de communication Homme->Machine.
* Interaction directe : Avec une interface gestuelle pure, la machine n'analyse pas les modifications induites sur un périphérique, mais capte le mouvement même de la main : c'est celle-ci qui devient le périphérique, éliminant la nécessité de prise en compte cognitive d'un dispositif externe à l'usager.
On distingue trois types d'interfaces gestuelles pures:
* Interfaces des réalités virtuelles, basées sur la manipulation directe d'objets représentés en trois dimensions. L'utilisateur est plongé dans un monde virtuel, fonctionnant comme le monde réel, mais dans lequel l'ordinateur interprète toutes ses actions comme des commandes. Myron Krueger [Krueger 1989] décrit de nombreux exemples de ce type d'interfaces.
* Interfaces multimodales: Étymologiquement, ces interfaces visent à interpréter en parallèle plusieurs des canaux de communication humains (voix, geste, direction du regard), pour améliorer l'interaction. La plupart des expériences menées dans ce domaine ont pour objectif de rapprocher l'utilisation d'une machine d'une communication naturelle entre humains [Bolt 1980].
* Langages gestuels opératifs: Ces interfaces utilisent la reconnaissance de langages gestuels spécialisés. K. Murakami et H. Taguchi [Murakami et Taguchi 1991] reconnaissent des mots de la langue des signes japonaise (langue utilisée par les sourds-muets). D. Sturman [Sturman 1992] reconnaît un vocabulaire utilisé pour orienter les grues sur des chantiers. Morita et al. [Morita, et al. 1991] utilisent un gant numérique et une baguette pour permettre à un chef d'orchestre de diriger un orchestre synthétique.
L'application que nous proposons entre dans cette dernière catégorie. Nous nous inspirons de l'approche de réalité augmentée, définie par Pierre Wellner, Wendy Mackay et Rich Gold [Wellner, et al. 1993]. Cette démarche s'oppose aux réalités virtuelles : nous ne cherchons pas à recréer un univers synthétique pour y plonger l'utilisateur, mais à améliorer l'existant par des techniques simples mais soigneusement évaluées, discrètes et compatibles avec notre expérience du monde réel. En étendant le modèle qui sous-tend notre application, nous entendons également appliquer nos résultats à la réalisation d'interfaces multimodales.
Une des raisons pour lesquelles, à notre avis, ces systèmes sont difficilement utilisables est le syndrome d'immersion : la machine capte tous les gestes de l'utilisateur ; ce dernier peut vouloir ou avoir besoin d'agir dans le monde réel alors que la machine interprète ses gestes, contre sa volonté. Un des problèmes important à résoudre avec les interfaces gestuelles pures (comme avec la reconnaissance de la parole), consiste donc à détecter efficacement l'intention de l'utilisateur, avant d'interpréter la nature de ses actions. D'autres problèmes doivent également être résolus pour que ces interfaces puissent se répandre : les périphériques capteurs existant sont encore coûteux, inconfortables (l'utilisateur est relié par un cordon à la machine) et peu fiables.
Ayant caractérisé certains aspects de l'interaction gestuelle pure, nous avons réalisé une application prenant en compte les avantages et les limites du geste. Son objectif n'est pas tant d'offrir des fonctionnalités inusitées et des algorithmes performants que de s'intégrer de façon transparente dans un environnement de travail habituel. Nous ne prétendons pas pour autant fournir un produit effectivement industrialisable (le matériel utilisé ne pouvant être répandu), mais tout au moins nous assurer de son utilisabilité dans un contexte réel et concret. Notre parti-pris a été de choisir des solutions simples mais basées sur une étude de la nature de l'interaction gestuelle et des conséquences induites sur un système de reconnaissance. Notamment, nous n'avons pas utilisé dans notre interface de modélisation de l'usager et de l'application : ces modèles sont expérimentaux et nécessitent des méthodes logicielles lourdes. De plus, ils engendrent une dépendance du modèle d'interaction vis-à-vis de l'application qui ne nous a pas été nécessaire.
Nous utilisons ce système pour assister la présentation interactive (Figure VI.1.1). Un rétroprojecteur reproduit l'écran de l'ordinateur sur un panneau de projection. Le présentateur (notre utilisateur) porte le gant numérique et se sert de commandes gestuelles pour diriger sa conférence. Bien que le système capte tous les gestes de l'utilisateur, celui-ci reste libre d'interagir dans le monde réel, pour communiquer ou utiliser d'autres appareils. En effet, les commandes sont interprétées par le système seulement si :
* l'utilisateur désigne explicitement avec la main une "zone active", en l'occurrence la zone de projection murale.
* il adopte certaines postures de la main reconnues comme des configurations de début de commande gestuelle. L'utilisateur peut donc désigner des portions de l'écran sans pour autant déclencher de commande.
Les types de gestes reconnus sont choisis de façon à correspondre à des gestes usuels, facilitant ainsi l'apprentissage et l'utilisation du système. Le jeu de commandes évite soigneusement les postures correspondant à un état de repos du bras et de la main : ainsi, l'utilisateur ne déclenchera pas de commande involontairement. Toute commande gestuelle reconnue ne peut résulter que d'un "effort" intentionnel de l'utilisateur.
Figure VI.1.1 : Système de présentation assistée par
ordinateur utilisant
la reconnaissance de gestes de la main.
Cette application apporte quelques avantages par rapport aux outils classiques d'aide à la présentation : on constate à l'utilisation que la plupart des commandes gestuelles sont exécutées presque inconsciemment ; le présentateur accompagne sa présentation de gestes naturellement. Lorsqu'il a une certaine pratique de l'application, il se tourne légèrement et instinctivement vers l'écran, et les gestes de passage à l'écran suivant, retour au sommaire, etc., sont effectués sans que le déclenchement des commandes n'engendre d'effort cognitif perceptible. Avec les dispositifs classiques la présentation est en quelque sorte hachée par le passage d'écran en écran, l'utilisation des commandes gestuelles permet de joindre le geste à la parole, d'accompagner la présentation orale pour mettre en valeur son articulation.
Le système permet au conférencier d'adapter librement sa présentation à l'auditoire, de revenir à des passages précis pour répondre aux questions ou d'éliminer des portions non adaptées au public. Certaines fonctions permettent d'ajouter un caractère multimédia au système : le défilement automatique permet de déclencher des animations, des commandes peuvent être ajoutées pour contrôler d'autres dispositifs de présentation : enregistrements audio ou vidéo, démonstration automatisée du fonctionnement d'un logiciel.
Dans la suite de notre exposé, nous présentons les méthodes qui ont permis la réalisation de cette interface gestuelle, les choix faits et les limites que nous avons rencontrées.
Afin de pouvoir distinguer les gestes adressés au système de ceux concernant l'environnement, notre modèle requiert la définition de zones actives. Ces zones sont des surfaces en deux dimensions, par exemple la projection d'un écran d'ordinateur sur un mur. Les gestes ne sont interprétés que si l'utilisateur désigne une zone active, c'est-à-dire que la projection de son poignet dans la direction du bras sur le plan défini par la zone active intersecte la surface délimitée.
Chaque commande gestuelle est définie par une posture de départ, une dynamique et une posture de fin optionnelle. Ainsi, l'intention d'effectuer une commande n'est exprimée que par la conjonction d'une désignation de la zone active, l'adoption d'une posture de début de geste et une trajectoire globale correspondant à une commande reconnue. Il n'est pas nécessaire de maintenir la main immobile lors de l'adoption d'une posture de départ, ce qui permet d'enchaîner les commandes en souplesse. Lorsque la main cesse de désigner la zone active lors de l'expression d'une commande, celle-ci est reconnue. Ceci permet de se passer de la posture de fin, ou plus simplement de déclencher les commandes par un simple abaissement du bras.
La conjonction des degrés de liberté capturés par le gant numérique et de la zone active défini en tout 36 dimensions non indépendantes interprétables dans un geste : la position (X, Y, Z) et l'orientation (lacet, tangage et roulis) du poignet dans l'espace, sa vitesse dans chacune de ces composantes ([[partialdiff]]X, [[partialdiff]]Y, [[partialdiff]]Z, [[partialdiff]]lacet, [[partialdiff]]tangage, [[partialdiff]]roulis), les positions et vitesses de chaque phalange (le gant capture les mouvements de 10 phalanges) et enfin la position désignée par le poignet sur la zone active (pX, pY et [[partialdiff]]pX, [[partialdiff]]pY). L'espace de définition des gestes et postures est donc particulièrement vaste e t les contraintes liant les dimensions capturées rendent son appréhension délicate. Nous inspirant de la table définie par Card, Mackinlay et Robertson [Card, et al. 1991] décrite au chapitre II, nous pouvons placer chaque dimension capturée et lui affecter un rôle parmi trois, présentées selon le tableau suivant :
| Utilisateur | Segmentation | Classification | |
| X, Y, Z
δX, δY, δZ | X | ||
| lacet, tangage
δlacet, δtangage | X | ||
| roulis | X | ||
| pX, pY | (si != 0) | paramètre | |
|
δpX,δpY δroulis | X | ||
| phalanges (10) | X | ||
| δphalanges (10) | X |
* Utilisateur : ce rôle signifie que nous ne nous servons pas de la dimension capturée directement. Dans le cas de la position et l'orientation du poignet dans l'espace (X, Y, Z, l, t et r), il nous paraît souhaitable que l'utilisateur puisse se déplacer librement dans la pièce, et émettre toute commande sans avoir à atteindre une position précise. Ces dimensions ne sont donc pas interprétées. Nous récupérons partiellement les dimensions perdues par la position du pointeur dans la zone active (pX et pY). Ainsi, nous perdons moins d'information analysable tout en acquérant une indépendance par rapport à la position d'où sont émises les commandes.
* Segmentation : ces dimensions sont affectées à la segmentation des gestes (postures de début et de fin de geste). Afin de rendre les postures plus reconnaissables par l'utilisateur et plus faciles à reconnaître par le système, ces dimensions sont discrétisées : nous considérons 7 orientations du poignet, 4 niveaux de pliure pour chaque doigt et 2 pour le pouce. Il existe ainsi en théorie 3584 postures identifiables par le système. Parmi celles-ci, les contraintes articulatoires de la main limitent à environ 300 les postures réalisables sans contorsions exagérées, dont 30 à 80 sont effectivement utilisables dans une interaction courante.
* Classification : Les mouvements de la projection de la main, des doigts, de rotation et de translation du poignet vers la zone active sont utilisés par l'algorithme de classification pour déterminer la commande effectuée d'après la dynamique du geste.
* Fatigue : Les commandes gestuelles font intervenir tous les muscles du bras, et celui-ci ne dispose pas de point d'appui. Elles doivent donc impérativement être brèves pour ne pas engendrer à terme de fatigue.
* Imprécision : Le système ne capte pas les gestes avec une fidélité parfaite. De plus, l'utilisateur ne peut pas désigner à distance avec suffisamment de précision pour utiliser, par exemple, des programmes de C.A.O. ou de dessin. Avec notre système, la meilleure résolution utilisable est d'environ 10 pixels, ce qui permet de manipuler des objets symboliques tels que fenêtres et icônes, mais pas d'effectuer des tâches courantes telles que sélectionner du texte ou dessiner des objets.
* Capacités d'abstraction limitées : Certains types de commandes ne peuvent pas être traduites au moyen de commandes gestuelles intuitives : changer une police de caractère, enregistrer un fichier...
Afin d'éviter les difficultés engendrées par ces limitations, nous avons adopté un parti pris défini par Ben Shneiderman dans sa définition de la manipulation directe [Shneiderman 1983] : offrir un jeu de commandes basé sur des actions rapides, incrémentales et réversibles :
* Actions rapides, afin d'éviter la fatigue ;
* Actions incrémentales, c'est à dire permettant une construction progressive vers le but à atteindre, afin de guider l'utilisateur et lui permettre de mieux conceptualiser le fonctionnement de l'interface ;
* Actions réversibles, afin de pallier à l'imprécision des gestes, aux erreurs de reconnaissance ou à l'éventuelle exécution involontaire de commandes.
Pour contourner la limitation de capacités d'abstraction, les interfaces à manipulation directe proposent l'emploi de menus répertoriant les commandes sans équivalent métaphorique clair dans le modèle d'interaction proposé. Dans notre cas, l'utilisation de la reconnaissance vocale en complément au geste nous paraît tout indiquée pour répondre mieux à ce problème : elle permet de préserver l'aspect direct de l'interaction. En attendant une extension multimodale de notre modèle d'interaction, celui-ci s'avère adapté à la navigation dans un système complexe, la manipulation d'objets ou la télécommande d'appareils informatisés.
Cette correspondance entre la tension musculaire utilisée instinctivement, et l'expression des commandes nous offre un moyen simple de détecter efficacement l'intention de l'utilisateur. Elle correspond du point de vue vocal aux variations d'intonations qui distinguent l'ordre explicite du discours habituel. Ces intonations vocales sont cependant difficiles à détecter dans les systèmes actuels de reconnaissance de la parole. Elles ne correspondent pas non plus tout à fait à nos habitudes d'utilisation du canal vocal. C'est pourquoi le canal gestuel nous apparaît plus approprié dans de nombreux cas pour constituer le fil directeur de l'interaction, la parole permettant de préciser efficacement la nature de l'action envisagée, lorsqu'elle s'avère un média efficace.
Enfin, nous avons conçu une notation permettant la documentation exhaustive des commandes utilisables. Les notations actuelles de langages de signes sont complexes et incomplètes, car les langues qu'elles représentent n'ont pas de formalisation sous-jacente. Dans notre cas, la forme des commandes est clairement délimitée par notre paradigme d'interaction et le domaine de l'application. Nous avons donc pu réaliser une notation iconique simple, qui se veut accessible rapidement à des utilisateurs non spécialistes. Celle-ci permet la représentation de l'aspect dynamique de notre interface gestuelle.
Une commande gestuelle est représentée par un bloc de trois icônes, représentant respectivement la posture de début de geste, la dynamique du geste et la configuration de fin de geste qui déclenche l'exécution de la commande. Cette dernière est optionnelle, car la commande est exécutée dès lors que l'utilisateur, ayant commencé une commande, cesse de désigner la zone active (en abaissant son bras, par exemple). Les icônes de début (resp. de fin) de geste représentent la posture qui doit être adoptée par la main pour que le système débute (resp. termine) la reconnaissance d'un geste. Cette posture est schématisée. En effet, comme nous l'avons indiqué précedemment, les dimensions gestuelles utilisées pour l'analyse des postures sont discrétisées. Au lieu de considérer l'angle des articulations et l'orientation du poignet comme des valeurs variant continûment, seules 4 valeurs de flexion pour chaque doigt (2 pour le pouce) et 7 valeurs d'orientation du poignet sont prises en compte. Ces valeurs sont notées par les symboles suivants (Figures VI.2.1 et VI.2.2) :
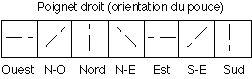
Figure VI.2.1 : notation de l'orientation du poignet.
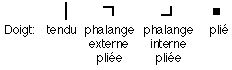
Figure VI.2.2 : notation des courbures de doigts.
L'icône centrale représente la dynamique du geste. Une flèche indique le mouvement général de la projection de la main sur la zone active. Cette flèche représente une trajectoire moyenne. Des variations d'amplitude ou de trajet sont admises par l'algorithme de reconnaissance. Le plus souvent ces variations sont utilisées pour préciser des paramètres de la commande : par exemple l'étendue de la zone à sélectionner, dans le cas de la commande "sélection", où les objets servant de paramètres, dans le cas de la commande "aller chapitre...". Si la commande réclame explicitement ces paramètres, un ou plusieurs cercles dans l'icône indiquent quels paramètres sont pris en compte. La dynamique des doigts est représentée lorsqu'elle n'est pas implicitement définie par la différence entre la configuration de début et celle de fin : une forme en "V" indique une flexion/extension d'un des doigts pendant l'expression de la commande. Enfin, une ligne parallèle au trajet de la main indique une variation de profondeur (pour indiquer par exemple l'action de pousser).

Figure
VI.2.3 : notation de la commande "Chapitre Suivant". Cet exemple utilise la
main droite. La commande est obtenue, lorsque l'utilisateur
désigne la zone active, en étendant la main, tournant le pouce
vers le bas (paume à droite) et en effectuant un mouvement de balayage
de la gauche vers la droite. La commande est reconnue lorsque l'utilisateur
referme la main, ou lorsqu'il ne désigne plus la zone active.
Cette notation nous permet de présenter le jeu de commandes complet de notre application dans son état actuel :

Figure VI.2.4 : le jeu de commandes complet de Charade.
* un contrôleur de périphérique adapté pour le gant numérique VPL Dataglove (utilisant notre propre méthode de calibration) ;
* une bibliothèque de reconnaissance de gestes de la main ;
* une application de construction interactive de jeux de commandes gestuels ;
* une interface (API) avec HyperCard, permettant d'envoyer des "événements gestuels" à une application HyperCard ;
* une application de présentation assistée par ordinateur utilisant HyperCard comme support logiciel.
Nous utilisons essentiellement deux algorithmes : un pour la détection de l'intention de l'utilisateur de s'adresser au système et la segmentation, et un autre pour la classification des commandes gestuelles. Ce dernier est une adaptation de l'algorithme défini par Dean Rubine [Rubine 1991] présenté au chapitre II.

Figure
VI.3.1 : Arbre de recherche d'une configuration de début de geste.
Il ne faut donc pas plus de 6 comparaisons de pointeurs par échantillon pour déterminer si une posture correspond ou non au début d'un ou plusieurs gestes.
Nous avons adapté cet algorithme à la classification de gestes de la main en ajoutant 12 caractéristiques : les variations des valeurs de flexion pour chaque doigt (10 degrés de liberté), la variation de distance entre la main et l'écran ainsi que la rotation totale du poignet (roulis) sur lui même pendant la durée du geste.
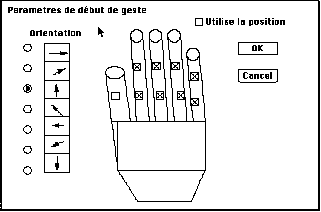
Figure VI.3.2 : Spécification interactive des paramètres de début de geste dans l'application d'apprentissage de "grammaires" gestuelles.
Les caractéristiques dynamiques du geste sont extraites d'exemples de gestes de chaque classe fournis par le concepteur de l'application. Une dizaine d'exemples par commande gestuelle suffit en général à permettre une reconnaissance indépendante de l'utilisateur.
Nous avons remarqué deux types d'erreurs :
* Les gestes qui diffèrent essentiellement par leur aspect dynamique (tels que page suivante x 2 et page suivante x 3) sont souvent confondus, surtout lorsque la variation dynamique concerne le mouvement des doigts. Ceci est en partie dû aux problèmes de calibration du gant et à sa résolution limitée. Mais nous envisageons également des améliorations de notre adaptation de l'algorithme de Rubine pour mieux prendre en compte la dynamique des doigts.
* La plupart des erreurs des débutants sont dues à une hésitation ou une pause lors de l'expression d'une commande : dans ce cas, l'analyse de la partie dynamique est totalement faussée, et le système peut reconnaître successivement plusieurs commandes erronées tant que l'utilisateur ne s'est pas rendu compte de ce qu'interprétait le système. Ces erreurs disparaissent avec quelque pratique, lorsque l'utilisateur intègre le principe de l'application et exécute les commandes plus naturellement.
Le taux d'erreur est suffisamment faible pour de pas engendrer de désagrément conséquent. L'acceptation du système et son efficacité sont par conséquent très bonnes. L'interface est facile à utiliser et les effets de présentation obtenus valent le (faible) temps d'apprentissage.
* La définition complète d'un modèle d'interaction gestuel, permettant de délimiter avec précision la structure des échanges entre le système et ses utilisateurs dans le cadre considéré.
* L'utilisation d'une zone active et de postures tendues pour détecter de façon naturelle l'intention de l'utilisateur et éviter le syndrome d'immersion.
* Une notation des gestes applicable à notre modèle.
* Quelques limitations du domaine d'application des interfaces gestuelles pures.
Nous envisageons ensuite deux améliorations du modèle : l'adaptation aux contraintes de la reconnaissance de gestes par caméra vidéo, et l'extension pour la prise en compte de la parole, afin de définir des interfaces multimodales guidées par le geste.
Afin de résoudre l'inconvénient majeur de notre interface, l'inconfort et le coût du gant numérique, nous envisageons d'utiliser la reconnaissance de gestes par caméra vidéo. Des systèmes nécessitant la pose de marqueurs sur la main sont déjà commercialisés. Fukumoto et al. [Fukumoto, et al. 1993, Fukumoto, et al. 1992] proposent une méthode de reconnaissance des gestes de la main utilisant deux caméras vidéo, sans aucun marqueur (figure VI.4.2). Ce système permet pour l'instant que de déterminer l'orientation générale de la main. Il ne peut être utilisé que comme un pointeur à distance. Cependant une amélioration des techniques de reconnaissance nous laisse entrevoir la possibilité de reconstituer le modèle d'interaction de Charade. Ainsi des systèmes de reconnaissance des visages tels les "Eigenfaces" de Turk [Turk et Pentland 1991] permettent de reconnaître avec un niveau de détail satisfaisant des détails saillants du visage. Les performances obtenues nous laissent espérer que les techniques de vision par ordinateur peuvent atteindre un niveau satisfaisant de reconnaissance des gestes. Une autre possibilité est l'utilisation de la détection de variations de champs de potentiel électrique, expérimenté par J. Lanier .
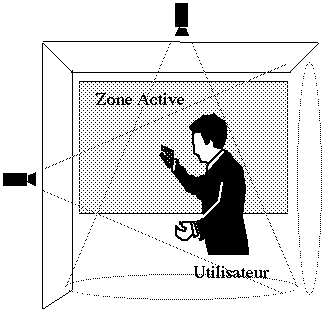
Figure VI.4.2 : configuration utilisée par
[Fukumoto, et al. 1993]
pour l'analyse de gestes de désignation par caméra.
Nous envisageons également de compléter l'utilisation de commandes gestuelles par la parole, afin de définir des interfaces multimodales guidées par le geste. Certains des problèmes à résoudre avec la parole sont communs aux interfaces gestuelles pures : une interface devient inutilisable si le modèle d'interaction qu'elle utilise ne permet pas une détection efficace de l'intention qu'a l'utilisateur de s'adresser au système. Ce problème n'est pas résolu avec les systèmes actuels de reconnaissance de la parole, alors que notre méthode de caractérisation s'est avérée efficace. C'est pourquoi nous proposons de définir des modèles d'interaction où la parole n'est utilisée qu'en complément du geste, pour permettre une expression plus concise des commandes, et non comme vecteur principal de l'interaction.
A titre d'exemple, les courtiers du MATIF utilisent un langage gestuel opératif pour communiquer à distance les ordres de vente et d'achats. À l'heure actuelle, les courtiers sont réunis dans une salle et communiquent entre eux, ainsi qu'avec des opérateurs situés sur un balcon et leur permettant d'interagir indirectement avec les marchés extérieurs, afin de permettre un arbitrage des cours en temps réel entre les différentes places boursières. Les opérateurs du balcon se contentent de rentrer les informations échangées dans les systèmes informatisés, et de refléter l'évolution des cours aux courtiers situés sur le parterre. Contrairement aux autres marchés, les marchés à terme d'instruments financiers n'envisagent pas de se virtualiser[9] et d'abandonner le principe de la corbeille, qui fonctionne de façon satisfaisante. Ainsi, le langage gestuel utilisé, inventé dans les années 1930, est promis à demeurer encore longtemps d'actualité. Ce langage présente de nombreux points communs avec les commandes de Charade : la structure des signes est très proche, et la plupart des signes ont une structure redondante permettant d'éviter les risques d'ambiguïté et de caractériser l'intention de communiquer.
Cette application est donc une bonne candidate à l'utilisation industrielle de modèles d'interaction gestuelle du type de celui de Charade.

Figure
VI.5.2 : exemples de signes utilisés par les courtiers des
marchés à terme d'instruments financiers
[MATIF Diffusion].
Dans un premier temps, une reconnaissance par caméra dans un contexte professionnel pourrait être aidée par la pose de marqueurs sur les mains des utilisateurs. Un système tel que le Elite Motion Analyser [Superfluo 1993] permet le suivi d'une centaine de points dans l'espace au moyen de plusieurs de plusieurs caméras, à une fréquence d'environ 100Hz. Le coût de ce système est cependant prohibitif (200 000 dollars).
Une application plus lointaine de Charade pourrait être le remplacement des télécommandes et contrôles à distance par une interaction gestuelle à distance dans un environnement domotique (figure VI.4.3). Un certain nombre de caméras judicieusement placées permettent de définir des zones actives pour tous les objets activables à distance. Il devient ainsi possible d'actionner les divers appareils électroménagers tels que le système audio-vidéo, la lumière, les rideaux, sans ce déplacer ni s'encombrer d'une télécommande.
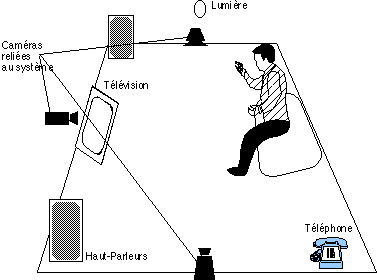
Figure VI.4.3 : une pièce active et quelques exemples d'objets contrôlés à distance par gestes.
L'avantage d'une interaction gestuelle pure du point de vue de la modélisation est que les dimensions captées appartiennent à l'aura même de l'utilisateur : il n'y a pas d'articulation entre les dimensions du système moteur humain et les capteurs du système qui rend la caractérisation exacte des actions de l'utilisateur difficile à décrire. L'articulation existe, mais elle est extérieure à l'utilisateur et incluse dans le système : il s'agit de l'utilisation des coordonnées portées sur la zone active plutôt que les valeurs brutes de position et d'orientation du poignet.
L'espace de définition des périphériques d'entrée de Card, Mackinlay et Robertson se révèle particulièrement utile pour décrire Charade : tout d'abord nous avons à maîtriser un espace complexe muni de nombreuses dimensions. Il n'est pas très utile de présenter les différentes dimensions captées pour une souris ou tablette graphique qui n'ont que 3 degrés de liberté. En revanche, l'organisation de 32 degrés de liberté réclame un peu plus de recul.
Le modèle d'interaction définit précisément la technique principale employée : utilisation de la désignation et d'une posture tendue, puis analyse de la dynamique du geste. Le style de l'interaction est très similaire à ceux des interfaces gestuelles à base de reconnaissances de marques. Il est possible d'utiliser la désignation d'objets dans la zone active ou des commandes gestuelles de changements de modes pour reproduire une interaction à base de menus.
En revanche, les aspects pragmatiques sont les plus déterminants et sont indispensables pour rendre le modèle d'interaction utilisable : l'utilisation de postures tendues, tout d'abord, mais aussi la présence d'échos lexicaux et syntaxiques, la structure du jeu de commandes gestuelles doivent être étudiés pour chaque application afin de permettre une interaction effective et éviter le syndrôme d'immersion.